How to Predict A Blockbuster

It’s hard to tell if a movie will make millions or flop–just ask Hollywood. Getting audiences to fork over cash for tickets is also only a small part of the battle–once a film comes out, word of mouth can turn a bomb into a success, or vice versa. And then there’s the long tail of revenue that comes after a movie’s theatrical run, in the form of streaming rights, rentals, physical media sales, merchandise, and so on.
Part of the difficulty from a statistical perspective is that one of the most defining elements for any movie is the plot–and plots are written in text, which is hard to break down into numbers or categories. New deep learning models make it possible for computers to analyze text on a more substantive level, turning the description of a movie into coordinates in a numeric space. From there, I trained two algorithms to predict how popular a movie would be as well as how much people would like it. If you just want to play around with them, you can do so here:
https://moviepredictions.streamlit.app/
Turning Text Into Numbers
Before I get into that, a few words about how this process actually works. To start off with, I grabbed data on each movie, including its description (which usually encompasses a high-level overview of the plot), how many people left a rating for the movie, and the average rating they assigned it. I consider these latter two quantities as good proxies for how popular a movie is as well as how good people think it is. There’s a very tight correlation (r=0.75), for example, between how many votes a movie receives and how much money said movie made at the box office. And the movies with the highest average score tend to be the ones that critics rate highly, that compete for Oscars, top Best Of lists, and so on.
To further augment the data, I also used descriptive tags1 that I pasted to the end of each text. These tags include miscellaneous adjectives (“weird”, “happy”), genres (Drama, Romance, Action, etc.), and styles (“noir”, “French new wave”), among other words. And as a further boost to the model’s accuracy, I added the budget of each movie from the Movie Database data. This helps the model know whether a film is a huge blockbuster or a small indie film, which obviously has a major bearing on how many people will watch it.
With the movie descriptions, tags, and budgets in hand, I built a model to predict the vote count and average score2. The model essentially ingests the text and turns it into a list of numbers that roughly correspond to the meaning of the words. This is a bit like what deep learning models do, except on a substantially smaller scale and instead of trying to predict subsequent words, we’re training the model to predict vote counts and scores.
How Do the Models Do?
In short: quite well. Based on the description, tags, and budget, I can predict how many votes a film will get to within about 600 votes, for an R2 value of around 0.55.
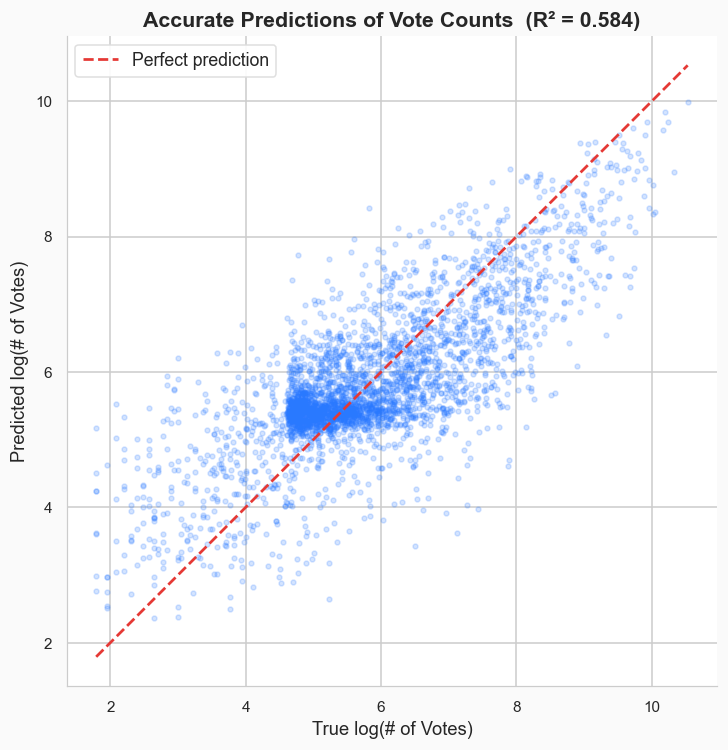
For average score, the predictions are typically accurate to within about 0.5 on a 10 point scale.
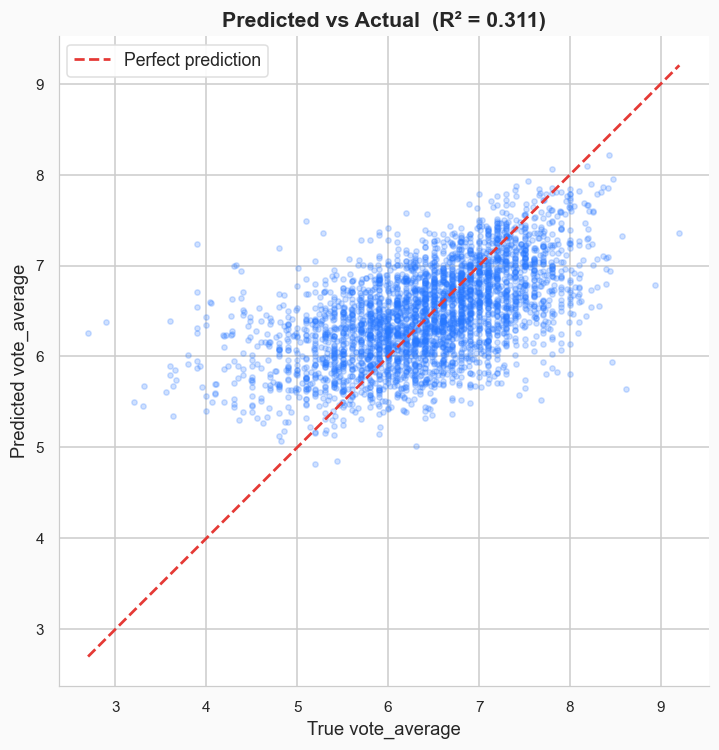
That means you can tell something that’s likely to be great from something that’s likely to be terrible. The R2 value is much lower (R2=0.31), however, which makes sense to me; the best plot, style, and budget in the world can’t guarantee that your lead actor will turn in an Oscar-worth performance, or that your editor won’t chop the movie into incoherence, and so on. You can contrast that with how many people will see the movie (proxied by vote count), where a high budget and a creative setting is likely to get people in the theater door, even if they don’t end up enjoying the movie.
Weird Foreign Fantasies, Based on a Book
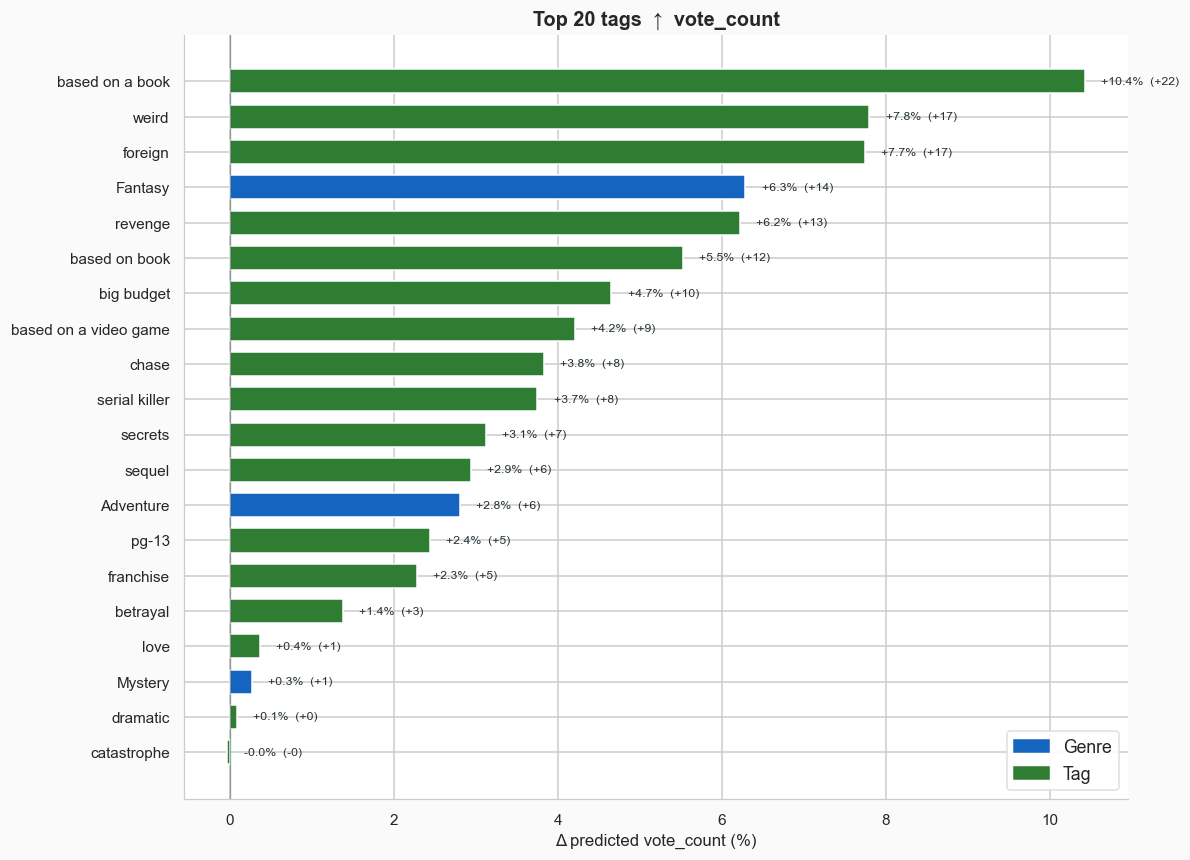
As one final interesting wrinkle, we can use the models to learn what kinds of descriptive tags contribute the most to a movie’s popularity and/or scores. The way this works is that I take each movie’s description and I attach the tag to the end of it, letting the model estimate how much that either boosts a movie’s score or detracts from it.
Let’s start with popularity, since that model is more accurate. The best tags if you want your movie to be popular are things like “based on a book,” “good,” and “weird.” The worst are nearly all specific genres that tend to be less popular: Documentary, TV Movie, and Animation carry the heaviest penalties.
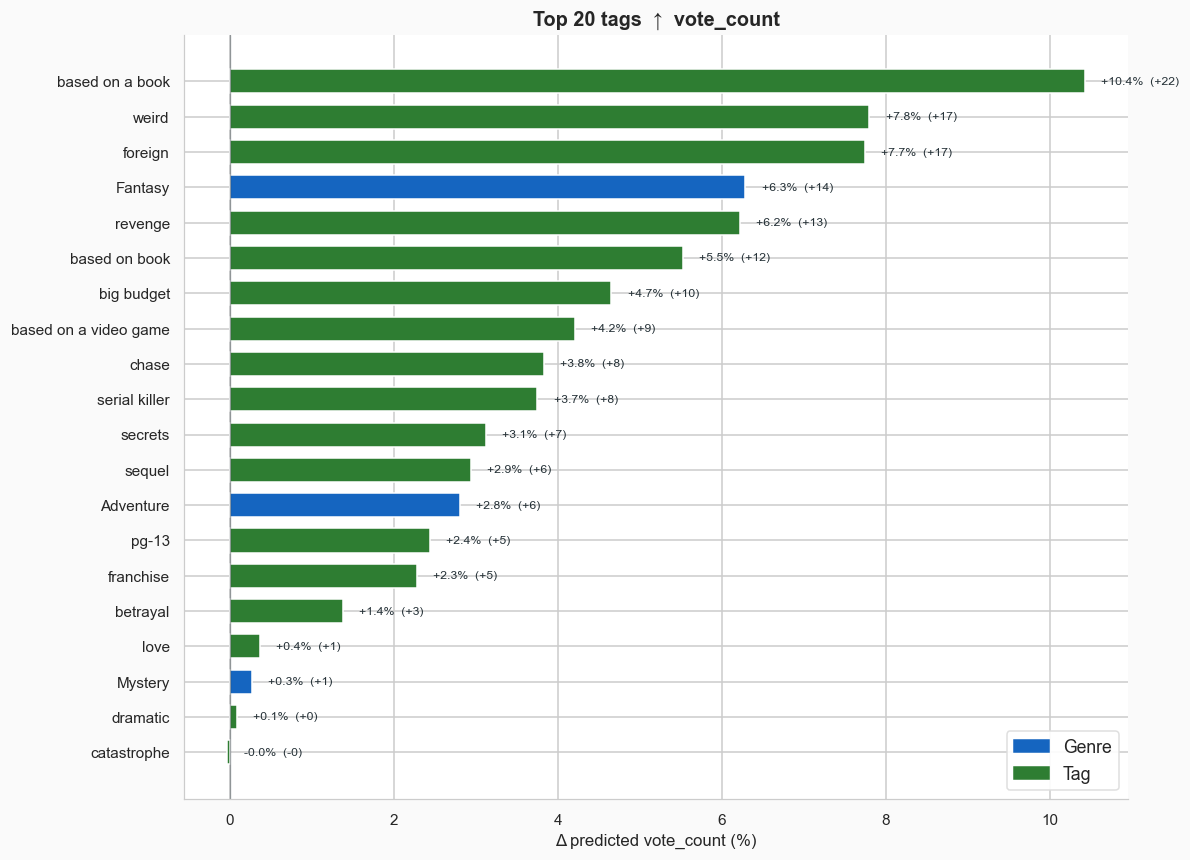
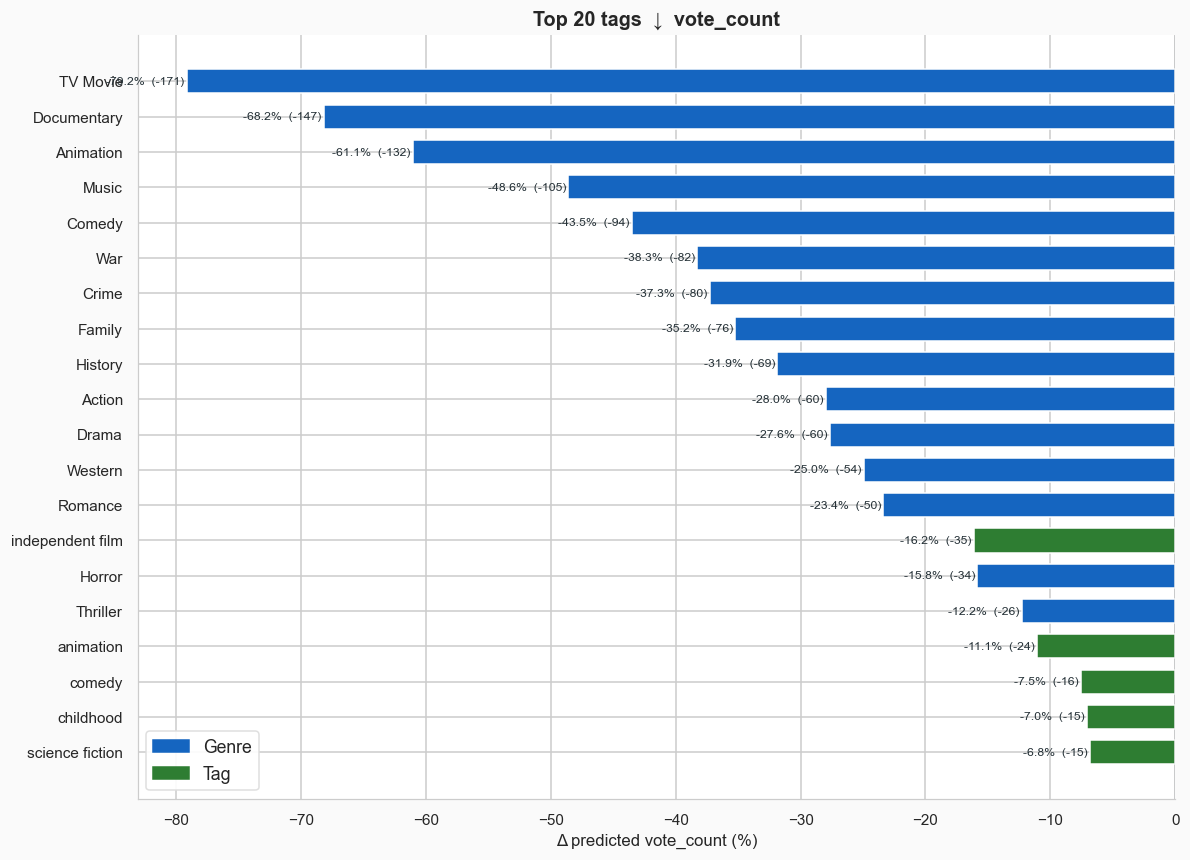
Overall, I’d say these lists make sense, with a handful of notable exceptions. I’m surprised that “foreign” movies score highly, but then again, not all foreign movies receive the “foreign” tag. It’s likely there’s some bias here: a movie that’s popular in the US from a foreign country might get tagged as foreign, whereas a movie that’s from Romania but never has any success in the US is also foreign, but since no one watches it, receives no tags.
The effects on popularity align with the shifts we’ve seen in Hollywood over the last few decades: more sequels, less original IP and more films based on books and video games.
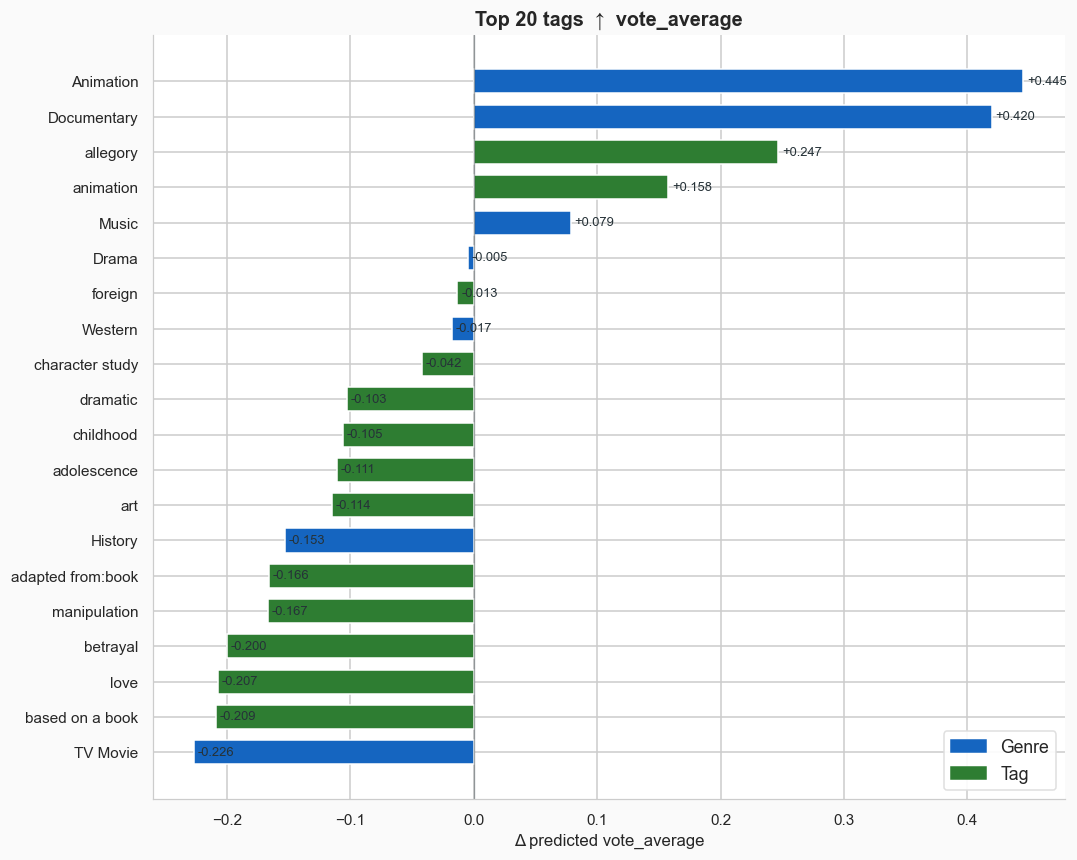
Turning to movie quality, some of the tags that boost quality the most are also the ones that reduce popularity. Genres like documentary and animation tend to be rated highly, but less watched. Meanwhile, movies based on books or video games are less liked, even though they are more popular (the same goes for sequels and franchises). Notably, no one likes teen movies.
Write Your Own Blockbuster Plot
If you want to see how accurate the models are for yourself, both are available in a Streamlit app here:
https://moviepredictions.streamlit.app/
Put in your description text, garnish with some tags and genres, then get back how well the algorithms think your film would perform, both in terms of percentiles and raw scores. Critically, much depends on how much money you can convince Hollywood producers (and/or Netflix execs) to give you for funding, and that’s not something my (or anyone’s) algorithm can tell you.
1 The freeform descriptive tags come from MovieLens, a large-scale study on movie tastes from the University of Minnesota. The genres come from The Movie Database.
2 For the technically inclined, I fine-tuned a Distilbert model to predict review counts and average scores based on the text of the description.